SOTA(State-of-the-Art)에서 "One-stage Anchor-free Oriented Object Detection"과 "Real-time Instance Segmentation"에서 1위를 차지한 논문입니다.
요약 정리
- instance segmentation(RTMDet-Ins)과 rotated object detection(RTMDet-R)으로 확장 가능
- backbone과 neck에서 호환 가능한 용량을 갖춘 overall architecture, 보다 효율적인 물체 감지기를 향한 large-kernel depth-wise convolutions을 갖춘 새로운 기본 빌딩 블록으로 구성
- 동적 레이블 할당에서 matching costs을 계산할 때 soft labels을 추가로 도입
- 모델 크기를 조정하여 다양한 애플리케이션 시나리오에 적합한 tiny/small/medium/large/extra-large 모델 제공
Abstract
YOLO 시리즈를 능가하는 효율적인 실시간 객체 감지기를 설계하는 것을 목표로 하며, 인스턴스 분할, 회전된 객체 감지와 같은 많은 객체 인식 작업에 쉽게 확장 가능합니다. 보다 효율적인 모델 아키텍처를 얻기 위해 large-kernel depth-wise convolutions으로 구성된 basic building blocks으로 구성된 backbone 와 neck에서 호환 가능한 용량을 가진 아키텍처를 탐색합니다. 정확도를 향상시키기 위해 동적 레이블 할당에서 matching costs를 계산할 때 soft labels을 추가로 도입합니다. RTMDet은 다양한 애플리케이션 시나리오를 위해 tiny/small/medium/large/extra-large 모델 크기로 best parameter-accuracy trade-off을 달성합니다.
코드와 모델은 아래에 공개되었습니다
Object Detection by mmdetection
Oriented Object Detection by mmrotate
1.Introduction
RTMDet은 인스턴스 분할과 회전 객체감지도 수행할 수 있습니다. 개선 사항은 large-kernel depth-wise convolutions을 사용한 더 나은 표현과 동적 레이블 할당에서 soft labels을 사용한 더 나은 최적화에서 비롯됩니다.
먼저 모델의 backbone과 neck의 basic building blocks에서 large-kernel depth-wise convolutions을 활용하여 global context를 캡처하는 모델의 기능을 향상시킵니다.
빌딩 블록에 depth-wise convolution을 직접 배치하면 모델 깊이가 증가하여 추론 속도가 느려지므로 모델 깊이를 줄이기 위해 빌딩 블록의 수를 더 줄이고 모델 너비를 늘려 모델 용량을 보상합니다.
neck에 더 많은 매개변수를 넣고 backbone과 호환되는 용량을 만들면 더 나은 속도 정확도 트레이드 오프를 얻을 수 있음을 관찰했습니다.
모델 아키텍처의 전반적인 수정은 모델 재매개변수화에 의존하지 않고 RTMDet의 빠른 추론 속도를 허용합니다.
모델 정확도를 개선하기 위해 교육 전략을 재검토합니다. data augmentations, optimization, training schedules의 더 나은 조합 외에도 ground truth boxes와 model predictions을 일치시킬 때 hard labels 대신 soft labels을 도입하여 기존의 동적 레이블 할당 전략을 더욱 개선할 수 있음을 경험적으로 발견했습니다. 이러한 설계는 고품질 매칭을 위한 cost matrix의 식별력을 향상시킬 뿐만 아니라 레이블 할당의 노이즈를 줄여 모델 정확도를 향상시킵니다.
커널과 마스크 기능 생성 헤드를 추가하기만 하면 RTMDet은 약 10%의 추가 매개변수만으로 인스턴스 분할을 수행할 수 있습니다.
회전된 개체 감지의 경우 RTMDet은 box regression layer의 차원(4에서 5로)을 확장하고 rotated box decoder로 전환하기만 하면 됩니다.
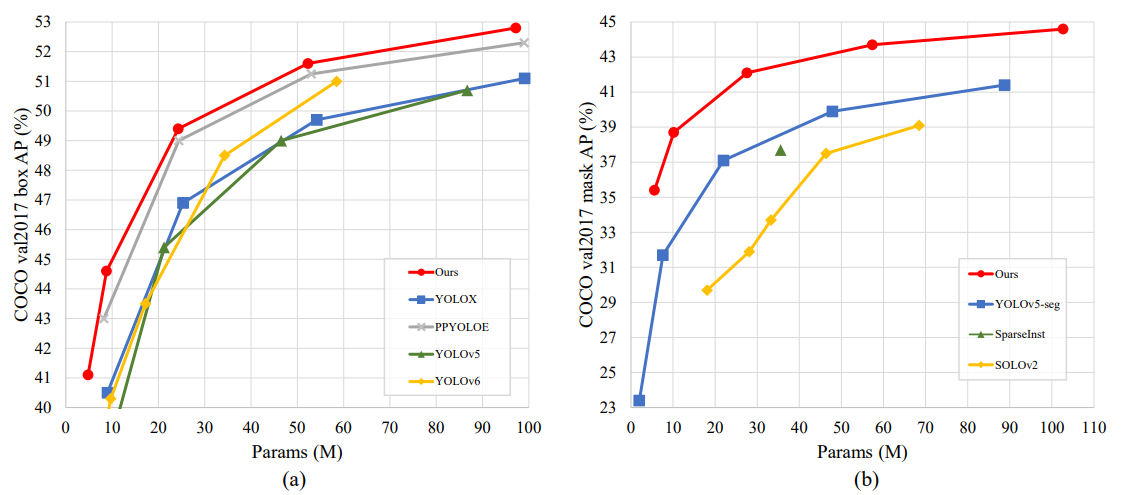
매개변수와 정확도 비교
(a)real-time object detectors (b)one-stage instance segmentation
2.Related Work
물체 감지(Object Detection)는 장면에서 물체를 인식하고 위치를 파악하는 것을 목표로 합니다. 실시간 응용의 경우, 기존 작업은 주로 two-stage 검출기 대신 앵커 기반 또는 앵커가 없는 one-stage 검출기를 탐색합니다. 인스턴스 분할(Instance segmentation)은 관심 있는 각 객체에 대한 픽셀당 마스 크를 예측하는 것을 목표로 합니다. 회전된 물체 감지(Rotated Object Detection)는 물체의 위치 및 범주 외에도 물체의 방향을 추가로 예측하는 것을 목표로 합니다
3.Methodology
3.1.Macro Architecture
one-stage 객체 감지기의 macro 아키텍처를 backbone, neck, head로 분해합니다.
CSPDarkNet을 backbone 아키텍처로 채택합니다. 여기에는 4개의 단계가
포함되어 있으며 각 단계는 몇 가지 basic building blocks으로 쌓여 있습니다.
neck은 backbone에서 multiscale feature pyramid를 가져오고 pyramid feature map을 향상시키기 위해
top-down과 bottom-up feature propogation과 함께 backbone과 동일한 basic building blocks을 사용합니다.
마지막으로 감지 헤드는 각 스케일의 특징 맵을 기반으로 객체 경계 상자와 해당 범주를 예측합니다.
이러한 아키텍처는 일반적으로 일반 객체와 회전된 객체에 적용되며 커널 및 마스크 피처 생성 헤드에 의한 인스턴스 분할을 위해 확장될 수 있습니다.
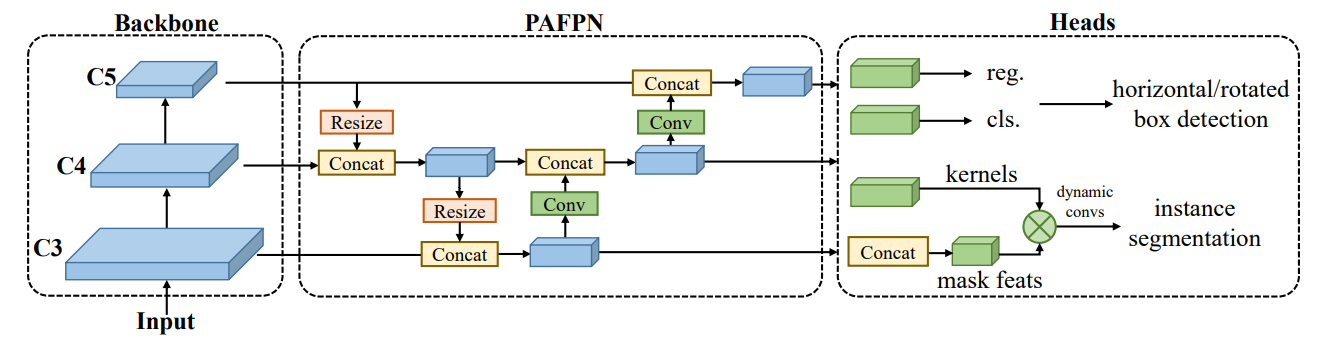
Macro 아키텍처
large kernel depth-wise가 있는 CSP-blocks를 사용하여 backbone을 구축합니다. C3, C4 및 C5로 표시된 multilevel features은 backbone에서 추출된 다음 backbone과 동일한 블록으로 구성된 CSP-PAFPN에 융합됩니다. 그런 다음 공유 컨볼루션 가중치와 분리된 배치 정규화(BN) 레이어가 있는 감지 헤드를 사용하여 (회전된) 경계 상자 감지에 대한 분류와 회귀 결과를 예측합니다. 인스턴스 분할 작업을 위해 Extra heads를 추가하여 dynamic convolution kernels과 dynamic convolution kernels을 생성할 수 있습니다3.2.Model Architecture
Basic building block
backbone의 큰 효과적인 receptive field는 이미지 컨텍스트를 보다 포괄적으로 캡처하고 모델링하는데 도움이 되므로 객체 감지 및 분할과 같은 밀도 높은 예측 작업에 유용합니다. CSPDarkNet의 기본 구성 요소에 5x5 깊이별 컨볼루션을 도입하여 효과적인 수용 필드를 증가시켰습니다. 이 접근 방식은 보다 포괄적인 상황별 모델링을 허용하고 정확도를 크게 향상시킵니다.
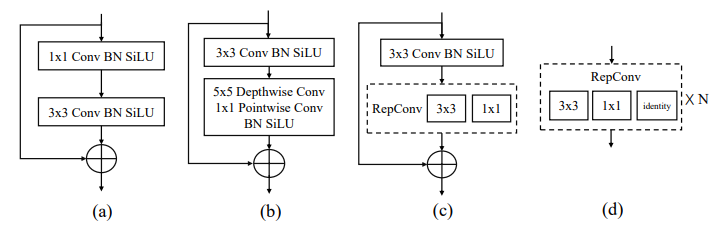
Different basic building blocks
(a) DarkNet 기본 병목 블록
(b) large-kernel depth-wise 컨볼루션 레이어가 있는 병목블록
(c) re-parameterized convolution을 사용하는 PPYOLO-E
(d) YOLOv6
Balance of model width and depth
Large-kernel depthwise convolution에 이어 추가 point-wise convolution으로 인해 기본 블록의 레이어 수도 증가합니다. 이는 각 레이어의 병렬 계산을 방해하여 추론 속도를 감소시킵니다. 이 문제를 해결하기 위해 각 backbone 단계의 블록 수를 줄이고 블록의 너비를 적당히 늘려 병렬화를 높이고 모델 용량을 유지하여 결국 정확도를 희생하지 않고 추론 속도를 향상시킵니다.
Balance of backbone and neck
neck에 있는 기본 블록의 확장 비율을 높여 비슷한 용량을 갖도록 하여 backbone에서 neck으로 더 많은 매개변수와 계산을 배치하는 다른 전략을 채택하여 더 나은 computation-accuracy 트레이드 오프를 얻습니다.
Shared detection head
논문에서 다양한 설계들을 비교하고 스케일 간에 헤드의 매개변수를 공유하지만 정확성을 유지하면서 헤드의 매개변수 양을 줄이기 위해 서로 다른 배치 정규화(Batch Normalization) 레이어를 통합합니다. Batch Normalization은 추론에서 훈련에서 계산된 통계를 직접 사용하기 때문에 그룹 정규화와 같은 다른 정규화 계층보다 효율적입니다.
3.3.Training Strategy
Label assignment and losses
1단계 물체 탐지기를 훈련시키기 위해, 각 scale의 dense predictions는 다른 레이블 할당 전략을 통해 ground truth bounding boxes와 일치됩니다. 각 scale의 dense predictions는 서로 다른 레이블 지정 전략을 통해 실측 경계 상자와 일치합니다. 최근의 발전은 일반적으로 학습 손실과 일치하는 비용 함수를 일치 기준으로 사용하는 동적 레이블 할당 전략을 채택합니다. 그러나 비용 계산에는 몇 가지 제한 사항이 있습니다. 따라서 SimOTA 기반의 동적 소프트 라벨 할당 전략을 제안합니다. 비용 함수는 아래와 같습니다.
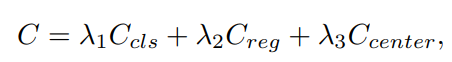
Ccls, Ccenter, Creg 는 각각 classification cost, region prior, regression에 해당합니다.
세 가지 비용의 기본 가중치는 λ1 = 1, λ2 = 3, λ3 = 1 입니다.
이전 방법은 일반적으로 이진 레이블을 사용하여 분류 비용 Ccl을 계산하므로 분류 점수가 높지만 경계 상자가 잘못된 예측을 통해 낮은 분류 비용을 달성할 수 있으며 그 반대의 경우도 가능합니다.
이 문제를 해결하기 위해 다음과 같이 Ccls에 소프트 레이블을 도입합니다.
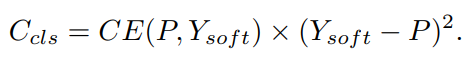
할당된 소프트 분류 비용은 다른 회귀 품질로 matching costs을 재가중할 뿐만 아니라 이진 레이블로 인한 시끄럽고 불안정한 매칭을 방지합니다. Generalized IoU를 회귀 비용으로 사용할 때 high-quality matches와 low-quality matches 간의 최대 차이는 1 미만입니다. 이로 인해 고품질 일치와 낮은 품질 일치를 구별하기가 어렵습니다. 서로 다른 GT-prediction 쌍의 match quality를 보다 차별적으로 만들기 위해 손실 함수에 사용되는 GioU 대신 회귀 비용으로 IoU의 로그를 사용하여 IoU 값이 낮은 일치 비용을 증폭합니다. 회귀 비용 Creg는 다음과 같이 계산됩니다.
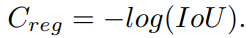
region cost Ccenter의 경우 아래와 같이 동적 비용의 매칭을 안정화하기 전에 fixed center 대신 soft center region cost을 사용합니다. 여기서 α와 β는 soft center region의 하이퍼 매개변수입니다. 기본적으로 α = 10, β = 3 으로 설정합니다.
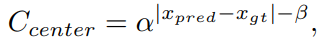
soft classification cost 할당은 서로 다른 regression qualities으로 matching costs의 가중치를 재가중할 뿐만 아니라 이진 레이블로 인해 발생하는 노이즈가 많고 불안정한 일치를 방지한다. 손실 함수에 사용되는 GioU 대신 회귀 cost로 IoU의 로그를 사용하여 더 낮은 IoU 값과 일치하는 비용을 증폭합니다.
Cached Mosaic and MixUp
데이터 로딩 요구를 줄이는 caching mechanism으로 MixUp 및 Mosaic을 개선합니다. cache를 활용하면 학습 파이프라인에서 이미지를 혼합하는 시간 비용을 단일 이미지를 처리하는 수준으로 크게 줄일 수 있습니다. cache operation은 cache length와 popping method에 의해 제어됩니다. 큰 cache length와 랜덤 popping method은 원래 cache되지 않은 MixUp과 Mosaic 작업과 동일하다고 간주할 수 있습니다. 한편, 작은 cache length와 FIFO(First-In-FirstOut) popping method은 반복된 증강과 유사하게 볼 수 있으며, 동일하거나 연속적인 배치에서 동일한 이미지를 다른 데이터 증강 작업과 혼합할 수 있습니다.
Two-stage training
강력한 데이터 증가에 의한 '노이즈' 샘플의 부작용을 줄이기 위해 YOLOX는 2단계 훈련 전략을 탐색했습니다. 첫 번째 단계는 Mosaic, MixUp, random rotation, shear을 포함한 강력한 데이터 증강을 사용하고 두 번째 단계는 random resizing, flipping과 같은 약한 데이터 증강을 사용합니다. 초기 훈련 단계의 강력한 증강에는 입력과 변환된 상자 주석 사이의 정렬 불량을 유발하는 random rotation과 shearing이 포함되므로 YOLOX는 두 번째 단계에서 회귀 분기를 미세 조정하기 위해 L1 손실을 추가합니다. 데이터 증강과 손실 함수의 사용을 분리하려면 이러한 데이터 증강를 제외하고 데이터 증강의 강도를 보상하기 위해 280 epoch의 첫 번째 훈련 단계에서 각 훈련 샘플의 혼합 이미지 수를 8로 늘립니다. 마지막 20 epochs에서 LSJ(Large Scale Jittering)로 전환하여 실제 데이터 분포와 더 밀접하게 정렬된 도메인에서 모델을 미세 조정할 수 있습니다. 학습을 더욱 안정화하기 위해 AdamW를 옵티마이저로 채택합니다.
3.4.Extending to other tasks
Instance segmentation
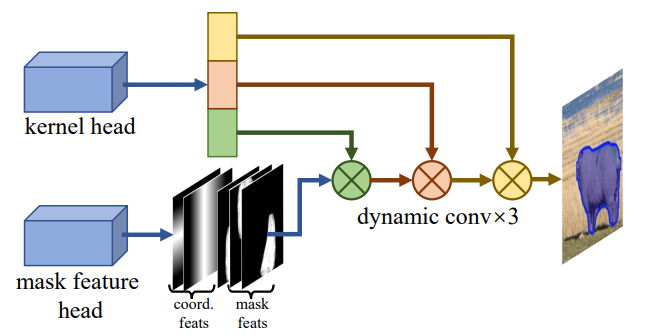
Instance segmentation branch
mask feature head는 4개의 컨볼루션 레이어를 가지고 있으며 neck에서 추출한 다단계 특징에서 8개 채널의 마스크 특징을 예측합니다. 두 개의 상대 좌표 기능이 마스크 기능과 연결되어 인스턴스 마스크를 생성합니다. 커널 헤드는 각 인스턴스에 대해 169차원 벡터를 예측합니다. 벡터는 세 부분으로 나뉘며(각각 길이는 88, 72, 9) 세 동적 컨볼루션 계층의 커널을 형성하는데 사용됩니다.
RTMDet을 기반으로 kernel prediction head와 mask feature head로 구성된 추가 branch가 추가됩니다. mask feature head는 다중 레벨 피처에서 8개 채널의 마스크 피처를 추출하는 4개의 컨볼루션 레이어로 구성됩니다. kernel prediction head는 각 인스턴스에 대해 169차원 벡터를 예측하며, 이는 3 개의 동적 컨볼루션 커널로 분해되어 마스크 특징 및 좌표 특징과의 상호 작용을 통해 인스턴스 분할 마스크를 생성합니다. 마스크 주석에 내재된 사전 정보를 추가로 활용하기 위해 box center 대신 동적 레이블 할당에서 이전 소프트 영역을 계산할 때 mass center of the masks을 사용합니다. 일반적인 규칙 에 따라 인스턴스 마스크에 대한 감독으로 dice loss을 사용합니다.
Rotated object detection
회전된 물체 감지. 회전된 물체 감지와 일반(수평) 물체 감지 사이의 고유한 유사성으로 인해 RTMDet을 RTMDet-R로 표시된 회전된 물체 감지기에 적용하는데 3단계만 걸립니다.
(1) 회귀 분기에 1x1 컨볼루션 레이어를 추가하여 회전 각도를 예측합니다.
(2) 회전된 상자를 지원하도록 bounding box coder를 수정합니다.
(3) GioU 손실을 순환 IoU 손실로 대체합니다.
또한 RTMDet-R은 RTMDet의 대부분의 매개 변수를 공유하므로 일반 감지 데이터 세트(예: COCO 데이터 세트)에 대해 미리 훈련된 RTMDet의 모델 가중치는 회전된 객체 감지를 위한 좋은 초기화 역할을 할 수 있습니다.
4.Experiments
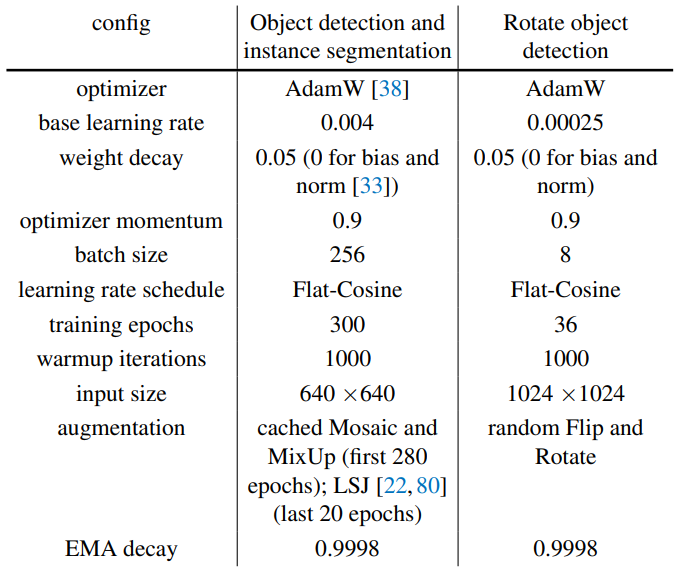
물체 감지, 인스턴스 분할, 회전 물체 감지를 위한 훈련 설정
5.Conclusion
이 논문에서는 모델의 아키텍처, 레이블 할당, 데이터 증강과 최적화를 포함하여 실시간 객체 감지기의 중요 구성요소를 종합적으로 연구하였습니다. 이 연구 결과는 RTMDet이라는 객체 감지를 위한 새로운 제품군 RealTime Models과 다양한 객체 인식 작업을 위한 파생 제품으로 이어졌습니다. RTMDet은 다양한 객체 인식 작업에 대해 다양한 모델 크기를 사용하여 industrial-grade applications에서 정확도와 속도 사이의 우수한 균형을 보여줍니다.